

A few years ago I was convinced we had a delivery problem. The evidence was everywhere. Features took weeks longer than estimated. The team was visibly busy, always in motion, always context-switching. Sprint reviews felt like triage sessions. My instinct was to look at the board, find where work was piling up, and fix that stage in the pipeline. I identified a bottleneck in code review. Senior engineers were overloaded. We redistributed review assignments, set WIP limits, started tracking review cycle time. It helped, a little, for a few sprints.
Then the same symptoms came back. Just upstream now.
It took me longer than I’d like to admit to realize I was solving the wrong problem. The real constraint wasn’t on anyone’s Jira board. It was in a recurring meeting I ran every Tuesday, where nothing got decided without my sign-off. It was in a deployment process that required three approvals, two of which routed to me. It was in the implicit rule, never written down, that architectural decisions needed to go through my inbox before moving forward.
I was the constraint. And I was the last person to see it.
This post is about the Theory of Constraints and why most engineering teams apply it too shallowly. If you manage a team or run an engineering organization, you’ve almost certainly read about TOC at the five-steps level. You’ve heard about identifying your bottleneck, exploiting it, and subordinating everything else.
What I want to talk about is the class of constraints that never appears in your metrics, never shows up in a retrospective, and is actively invisible to the person who created it: policy constraints and the leadership behaviors that produce them.
What TOC actually says, briefly
Eliyahu Goldratt introduced the Theory of Constraints in 1984 through a novel called The Goal. The core idea is simple enough to fit in one sentence: every system has exactly one primary constraint limiting its throughput, and improving anything that isn’t that constraint produces no real improvement in overall output.
The five focusing steps follow from this: identify the constraint, exploit it (squeeze more out of it without adding resources), subordinate everything else to it, elevate it if needed, then repeat because a new constraint will always emerge.
I’m not going to walk you through each step in detail. That content exists in abundance. What I want to focus on is what the framework says about types of constraints, because this is where most engineering teams stop reading too early.
Goldratt distinguished between physical constraints, resource constraints, and policy constraints. Physical and resource constraints are the ones everyone talks about: the single DBA, the slow CI build, the overwhelmed QA engineer. Policy constraints are different. They’re written or unwritten rules, explicit or implicit, that prevent the system from achieving higher performance. They don’t show up as a queue building somewhere. They show up as decisions that can’t get made, work that can’t start, and autonomy that never quite materializes.
Policy constraints are almost always the hardest to identify and the most common in mature engineering organizations. They’re also almost always created, sustained, and invisible to leadership.
The visible bottleneck is not the real problem
Here’s a pattern I’ve seen repeatedly. A team identifies slow code review as their bottleneck. They fix it: better tooling, clearer standards, review rotation. Throughput improves for a sprint or two. Then it stalls. They look again and find a new bottleneck: integration testing, or handoff to QA, or waiting for product clarification before the next feature can begin.
They celebrate fixing bottlenecks and keep moving them downstream. The team feels productive. The metrics actually improve. But delivery time stays stubbornly long and nobody can quite explain why.
The explanation, usually, is that the technical bottlenecks were real but secondary. The primary constraint was sitting somewhere else: in approval structures, in unclear ownership, in a process where certain decisions require a certain level of sign-off that isn’t available on the team’s timescale. Fixing code review speeds up work flowing into the constraint. It does nothing to the constraint itself.
Goldratt’s point was precise: any improvement made anywhere besides the constraint is an illusion. Not a small win, not progress with caveats. An illusion. That’s a strong claim and it’s worth sitting with.
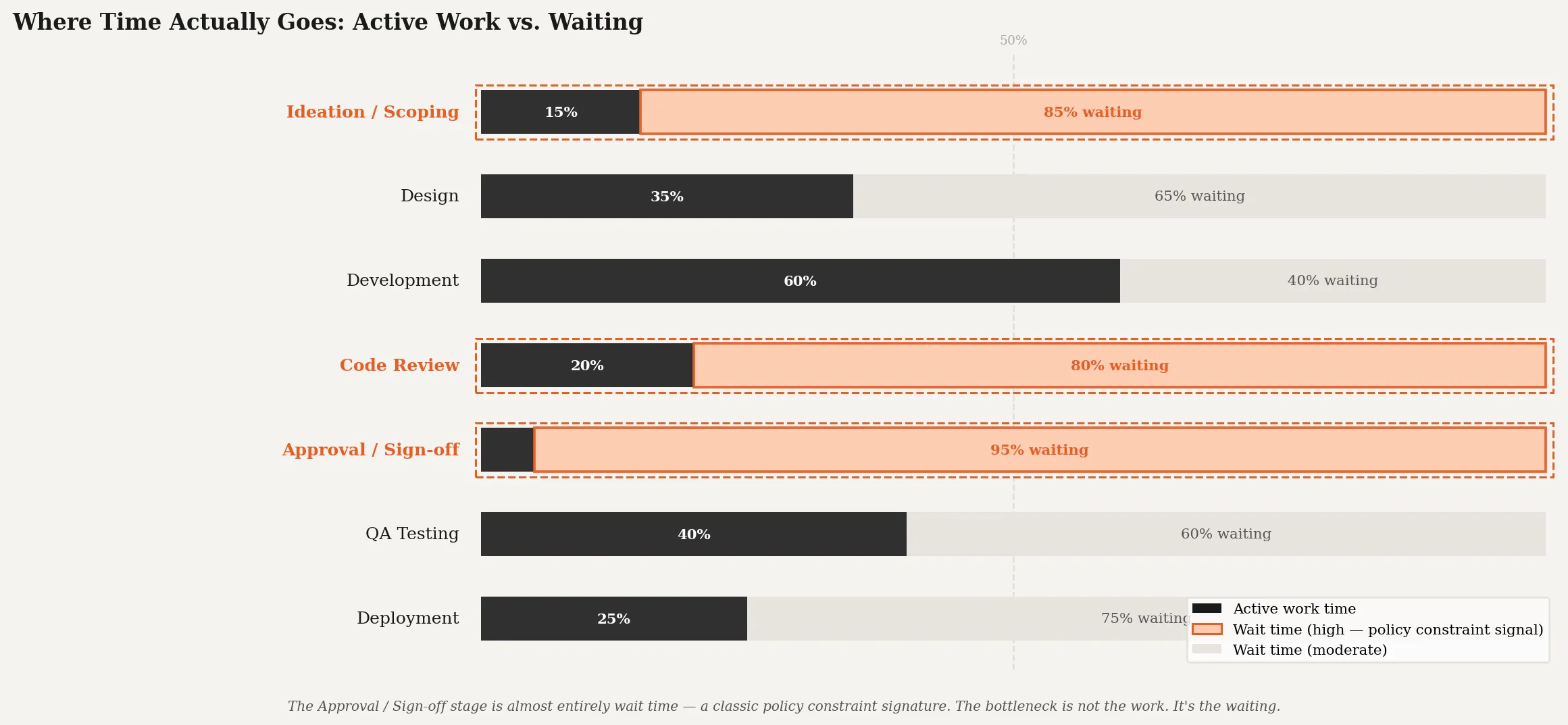
I’ve spent time mapping delivery pipelines in detail, tracking cycle times at each stage, building dashboards that show where work queues up. The honest lesson I came away with is that the data almost always points to a symptom rather than a root cause. The queue in front of QA is a symptom. What’s causing the queue? Sometimes it’s QA capacity. Often it’s that tickets arrive without adequate acceptance criteria because the product process is broken. Sometimes it’s that certain work bypasses normal flow entirely because a senior leader wants it fast-tracked, which shunts everything else backward without anyone noticing at the aggregate level.
These causes don’t appear on your Jira board. They require a different kind of investigation.
How to actually find policy constraints
The technique I find most useful is what I think of as the “why can’t we just” test. Walk through your delivery process and ask that question at every point of friction.
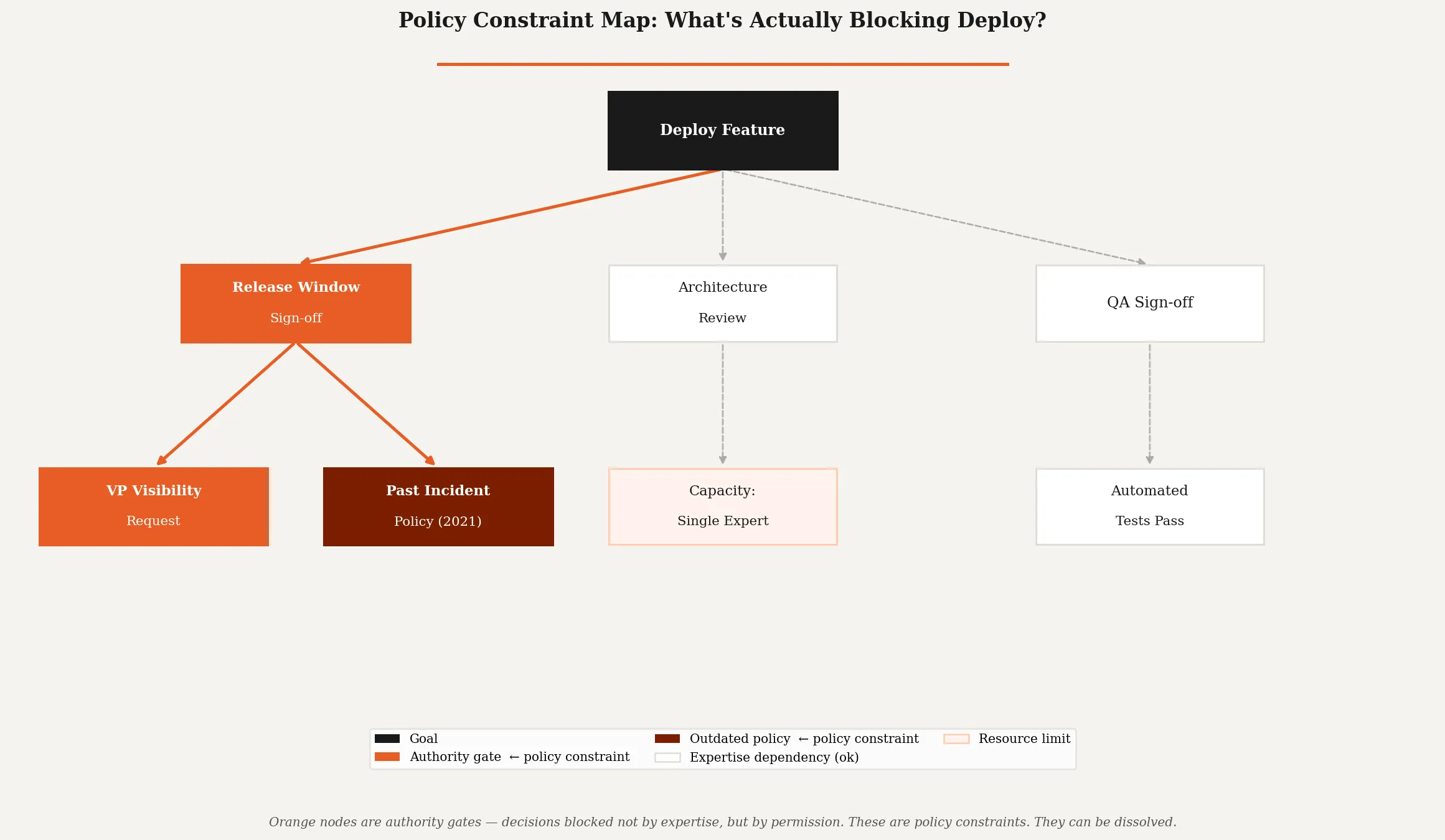
Why can’t we just deploy when the feature is ready? “We need a release window sign-off.” Why does that sign-off exist? “Because a VP wants visibility before anything goes to production.” Why does that VP want visibility at that point rather than earlier? “Because there was an incident three years ago and they added the step.”
That’s a policy constraint. Nobody intended to slow the team down. The incident was real. The response felt proportionate at the time. But the policy outlived the situation that created it and is now a permanent drag on throughput.
The questions to ask systematically:
- Where do teams wait for a decision from someone not on the team?
- Where does work require approval from someone unavailable during normal working hours?
- What cannot happen without a specific person’s involvement, not because of expertise, but because of authority?
- What process exists because of a past incident, and has anyone evaluated whether it still makes sense?
- What would the team do differently if the leader weren’t watching?
That last question is the most revealing. In my experience, engineers are exceptionally good at working around policy constraints when the alternative is shipping nothing. They find informal paths. They batch decisions to minimize approval wait time. They under-document to avoid triggering a review process. These adaptations are rational responses to a system that doesn’t trust them. The workarounds are the signal.
The leader as constraint
I want to be direct here, because most writing on this topic stays diplomatic.
Senior engineering leaders are among the most common constraints in their own organizations. Not because they’re bad leaders. Not because they don’t care about throughput. Because the same instincts that make someone good at leading a small team, being involved, having standards, wanting visibility, become system-level bottlenecks as the organization scales.
The approval that gave a junior team confidence at 10 people becomes a queue at 50. The architectural opinion that produced good decisions when one person could hold the whole system in their head becomes a gatekeeping mechanism when the system is too large for that. The “quick sync before we finalize this” that saved a project once is now a recurring tax on every decision.
(I’ve caught myself doing all of these. None of it felt like creating a constraint in the moment. It felt like being a responsible leader.)
The TOC framework applied honestly to leadership behavior asks a specific question: what decisions and activities require my unique capability, and which ones just require my permission? The former are genuinely hard to delegate. The latter are almost always policy constraints you can dissolve.
The test is simple: if you were unavailable for two weeks, what would stop?
Not what would go worse. Not what would benefit from your input. What would actually, operationally stop? Those are your constraints. Everything that would continue, perhaps differently than you’d like but continue, is subordination you’ve imposed on the system unnecessarily.
Why subordination is politically hard
Goldratt’s third step, subordinating everything else to the constraint, is the one most organizations skip or misapply. The instruction is straightforward: align all non-constraint activities to support the constraint’s maximum throughput, even if that means deliberately operating some resources below full capacity.
In practice, this is deeply uncomfortable.
It means telling a high-performing team to slow their output because feeding work faster into the constraint doesn’t help, it just builds a queue. It means some people look less busy. It means local efficiency metrics get worse for the sake of global throughput. And it means someone has to explain to an ambitious engineer or a driven team lead why they should do less.
Most engineering organizations reward local optimization. The team that ships most features, the individual who closes most tickets, the service with the best uptime. These metrics are visible and feel meaningful. TOC says they are often measuring the wrong thing, and that optimizing them can actively hurt overall system performance by hiding where the real work needs to happen.
I’ve tried to make this concrete by reframing the goal explicitly with my teams. The goal is not utilization. The goal is throughput. A team that is “only” 60% utilized but consistently unblocking the constraint is contributing more than a team running at 100% on work that queues behind a bottleneck they’re not helping to fix.
That’s a hard sell. It requires trust. It requires people to believe you’re measuring what matters rather than what’s easy. And it requires that the constraint actually gets fixed, not just identified and left.
Identifying your real constraint: a practical approach
I want to give you something concrete you can do after reading this.
Map your value stream. Not the happy path. The actual, messy path that work takes from idea to production. Include the informal steps: the Slack message asking for clarification, the meeting scheduled to get alignment, the ticket that waits because the relevant engineer is in planning all week. Include wait time, not just active work time. In my experience, the ratio of wait time to active work time in most software organizations is somewhere between 3:1 and 10:1. The bottleneck is almost always in the waiting, not the doing.
Then look for decisions that require specific authority. Not expertise: authority. These are almost always policy constraints rather than resource constraints. A resource constraint can be addressed by adding capacity or redistributing work. A policy constraint requires someone with the authority to change the policy to do so, and that person is frequently the one who benefits from the policy existing.
Then run the “why can’t we just” exercise from the end of the pipeline backwards. Start at deployment, work back toward ideation. Every friction point is either a genuine technical constraint, a resource constraint, or a policy constraint. Label them. You’ll find that the policy constraints cluster around the middle of the process, around the points where decisions cross team or organizational boundaries.
Finally, and this is the uncomfortable part: ask someone junior to do this analysis for you. Engineers two or three levels below you see the constraint with perfect clarity. They’ve been adapting to it for months. They’ve built workarounds. They have opinions about exactly what would change if leadership removed itself from the critical path. They often won’t volunteer this information unprompted because doing so feels presumptuous or unsafe.
Ask directly. Create conditions where the honest answer is welcome. The information is already in your organization. It’s just waiting for permission to surface.
What actually changes when you fix a policy constraint
When I eventually addressed the approval chain that was running through me, the change felt smaller than I expected and larger than I could have predicted.
The immediate effect was that certain decisions got made faster. Not dramatically faster, within the span of a few hours rather than a day or two. It didn’t feel revolutionary. But the compounding effect over several months was significant. Engineers started making decisions earlier in the process rather than waiting until the last moment to ask permission. They took more ownership of outcomes because they bore more responsibility for choices. The quality of the decisions, to my pleasant surprise, was fine.
The second-order effect was the one I hadn’t anticipated: teams started surfacing problems earlier. When the path from “I see an issue” to “we can address it” is short and doesn’t require escalation, people bring things up when they’re small. When every decision requires approval, people solve what they can locally and escalate only when a problem has grown large enough to justify the overhead. You end up discovering problems later, when they’re more expensive to fix.
Goldratt described this dynamic as the constraint suppressing information about the system’s actual state. When you remove a policy constraint, you don’t just increase throughput. You improve the quality of your organizational signal. You find out earlier what’s actually happening.
The constraint will move. Be ready.
One thing TOC gets right that most improvement frameworks ignore: the constraint moves when you fix it. This is not a failure. This is the system working.
When you remove a policy constraint from your own behavior, you should expect a new constraint to emerge somewhere else in the system. Maybe QA actually does become the bottleneck once the approval overhead is removed. Maybe the team’s architectural decision quality drops because they’ve been operating inside tight guardrails for so long that the muscle for independent judgment hasn’t developed. These are real and solvable problems, and they’re much better problems to have than a permanent constraint baked into leadership behavior.
The mistake is treating constraint resolution as a project with an end state. You removed the bottleneck, you declare victory, you move on. A few months later the same symptoms reappear and leadership is confused. TOC is a process of ongoing improvement, not a one-time fix. The five steps are a cycle, not a checklist.
I try to run a lightweight constraint review every quarter. Not a formal process. Just a structured conversation with team leads: where is work consistently getting stuck, and why? What decisions require input from outside the team that could be made inside the team if the right guardrails were in place? What permissions are people waiting for that could be pre-granted through a clearer policy?
This is the practice that makes TOC useful rather than just interesting as a framework.

On not confusing busyness with throughput
There’s a deeper idea underneath all of this that I want to name explicitly, because it affects how engineering leaders think about their job.
Most of us were promoted because we were individually effective. We solved problems, shipped features, made good technical decisions. The incentives that shaped us rewarded doing: output, velocity, completion. Management asks us to shift that orientation toward enabling rather than doing, but it doesn’t always give us a clear signal for when we’re succeeding.
TOC provides one such signal: throughput. Not the throughput of any individual or team, but of the whole system from idea to delivered value. If that number is improving, something is working. If it’s stagnant despite local improvements, you have a constraint you haven’t found yet.
The most important question an engineering leader can ask isn’t “Is the team busy?” It’s “Is value flowing?”
TOC even offers a concrete accounting lens for this: throughput accounting, which shifts focus from cost-cutting to measuring how fast value moves through the whole system. It’s a different way of evaluating decisions, and it reframes what “good” looks like for a leader.
Those two things can look identical from the outside and produce completely different outcomes. A team generating a lot of local activity while work piles up at an unaddressed constraint is busy and low-throughput at the same time. It’s an exhausting and demoralizing place to work, even if the sprint burndown looks healthy.
When I’ve been most effective as a leader, it wasn’t because I was maximally involved. It was because I had identified where my involvement was a bottleneck and deliberately removed it. That felt, at first, like doing less. It was actually doing the right thing.
Start here
If you want to apply this, start with one question this week.
Pick the last feature or project that took significantly longer than it should have. Map, informally and honestly, where time was spent. Not just active development time: total elapsed time, from the decision to start to the moment it was delivered. Find the longest wait. Ask why that wait existed. Follow the answer until it reaches either a person, a process, or a rule.
If it reaches a person: is that a capacity problem, or is that person a decision chokepoint? If the latter, that’s a policy constraint.
If it reaches a process: who created the process, and does it still solve the problem it was created to solve?
If it reaches a rule: where is the rule written down, and when was it last revisited?
The answer is already in your organization. You don’t need a consultant, a new tool, or a workshop. You need to ask honestly and then be willing to hear what comes back.
The constraint you’re looking for probably isn’t on any board. But the people on your team know exactly where it is. They’ve been working around it for months.
Go ask them.